R에서 (1)데이터를(CSV파일) 불러오는 방법과 (2)불러온 데이터의 구조를 확인하는 방법을 알아보자.
1. 기존 데이터 불러오기(read.csv())
R에서는 데이터를 외부 파일에서 불러올 때 read.csv() 함수를 많이 사용한다.
✔ read.csv("파일명.csv") : CSV 파일을 불러오는 함수
✔ header=F : 첫 행이 변수명이 아니라 데이터일 경우 사용
# CSV 파일 불러오기
dt <- read.csv("mydata.csv")
# 첫 행이 변수명이 아닐 경우
dt2 <- read.csv("mydata.csv", header=F)- 이때 파일 경로를 정확히 지정해야 하며, 작업 디렉토리에 파일이 있으면 경로를 간단히 입력할 수 있다.

🔥TIP: 만약 파일이 작업 디렉토리에 없다면 전체 경로를 지정하거나 file.choose()로 파일을 직접 선택할 수 있다
# 파일을 직접 선택하여 불러오기
dt <- read.csv(file.choose())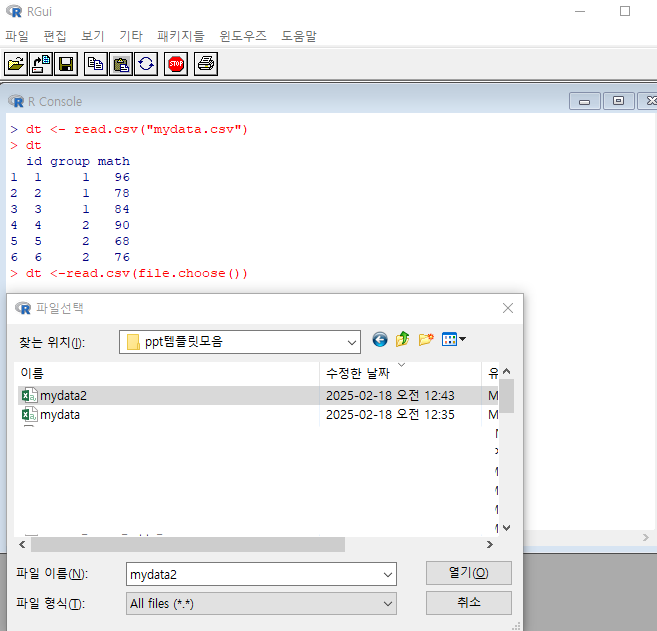
2. 데이터 구조 확인하기 (str(), head(), tail())
데이터를 불러온 후, 그 구조와 내용을 확인하는 것이 중요하다. R에서는 이를 위한 다양한 함수가 제공된다.
데이터 구조(strcutrue) 확인: str()
# 데이터의 구조 및 각 변수(컬럼)의 데이터 유형 확인
str(dt)
- str(): 데이터의 구조를 출력하여 각 변수의 데이터 유형과 값의 개수를 확인할 수 있다.
- 데이터가 잘 불러와졌는지, 각 열의 타입은 적절한지 확인할 때 유용하다.
데이터 일부 확인: head() / tail()
# 데이터의 처음 6개 행 출력
head(dt)
# 데이터의 마지막 6개 행 출력
tail(dt)- head(): 데이터의 앞부분 6행을 확인
- tail(): 데이터의 뒷부분 6행을 확인
- 데이터가 너무 많을 때, 일부만 빠르게 확인할 수 있는 방법이다.
🔥 head(), tail()은 Python에서는 5개의 행, R에서는 6개의 행을 불러온다.
🔥 두 언어 모두 출력 개수를 인자로 지정할 수 있다.
# R에서 10개 행 출력
head(dt, 10)
tail(dt, 10)
# Python에서 10개 행 출력
df.head(10)
df.tail(10)
3. 데이터 요약 정보 확인: summary()
데이터의 기본적인 통계 요약을 빠르게 확인하고 싶다면 summary() 함수를 사용한다.
데이터 요약 정보 확인: summary()
# 데이터의 각 변수에 대한 기초 통계 요약 출력
summary(dt)
- summary(): 각 변수의 최소값, 최대값, 평균, 중앙값 등을 확인할 수 있다.
- 특히 숫자형 변수에 대해서는 기초 통계량을, 범주형 변수에 대해서는 빈도수를 확인할 수 있다.
4. 결측값 확인
데이터에 결측값이 있는지 확인하고, 이를 어떻게 처리할지 결정하는 것이 중요하다.
이번에는 결측값 확인에 대해서만 알아보고, 결측값 처리에 대해서는 따로 다룰 예정이다.
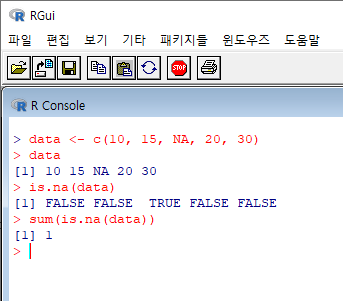
결측값 확인: is.na()
# 결측값이 있는지 확인
# TRUE/FALSE로 결측값 여부 확인
is.na(dt)- is.na(): 데이터의 각 값이 결측값(NA)인지 확인하는 함수. TRUE는 결측값, FALSE는 정상값을 의미한다.
결측값의 개수 확인: sum()
# 데이터 전체에서 결측값의 개수 출력
sum(is.na(dt))- sum(is.na()): 결측값의 총 개수를 확인. 이 정보를 바탕으로 결측값을 처리할 방법을 결정할 수 있다.
🔥 요약
| read.csv() | CSV 파일 불러오기 |
| str() | 데이터 구조 및 변수 확인 |
| head() | 데이터의 처음 6개 행 출력 |
| tail() | 데이터의 마지막 6개 행 출력 |
| summary() | 데이터의 기본 통계 요약 |
| is.na() | 결측값 여부 확인 |
| sum(is.na()) | 결측값 총 갯수 확인 |
'R' 카테고리의 다른 글
| [R 기초] 데이터 전처리 - 결측값 처리 (삭제 & 대체) (0) | 2025.02.23 |
|---|---|
| [R 기초] R에서 말하는 벡터(Vector)란? (0) | 2025.02.21 |
| [R 기초] R에서 자료 입력 및 저장하기 (0) | 2025.02.20 |
| [R 기초] R에서 작업 경로 설정하기 (0) | 2025.02.19 |
| [통계] R vs Python (0) | 2025.02.18 |